MAY 2, 2024 by Catherine Barzler, Georgia Institute of Technology
To avoid catastrophic climate impacts, excessive carbon emissions must be addressed. At this point, cutting emissions isn’t enough. Direct air capture, a technology that pulls carbon dioxide out of ambient air, has great potential to help solve the problem.
But there’s a big challenge. For direct air capture technology, every type of environment and location requires a uniquely specific design. A direct air capture configuration in Texas, for example, would necessarily be different from one in Iceland. These systems must be designed with exact parameters for humidity, temperature, and air flows for each place.
Now, Georgia Tech and Meta have collaborated to produce a massive database, potentially making it easier and faster to design and implement direct air capture technologies. The open-source database enabled the team to train an AI model that is orders of magnitude faster than existing chemistry simulations. The project, named OpenDAC, could accelerate climate solutions the planet desperately needs.
The team’s research was published in ACS Central Science.
“For direct air capture, there are many ideas about how best to take advantage of the air flows and temperature swings of a given environment,” said Andrew J. Medford, associate professor in the School of Chemical and Biomolecular Engineering (ChBE) and a lead author of the paper.
“But a major problem is finding a material that can capture carbon efficiently under each environment’s specific conditions.”
Their idea was to “create a database and a set of tools to help engineers broadly, who need to find the right material that can work,” Medford said. “We wanted to use computing to take them from not knowing where to start to giving them a robust list of materials to synthesize and try.”
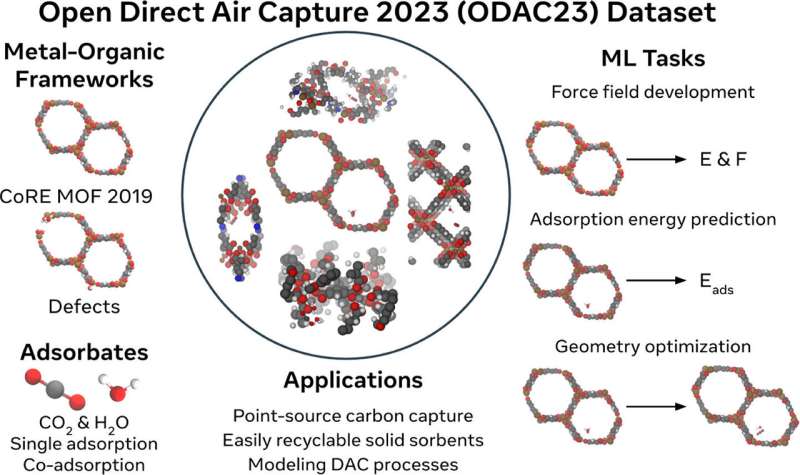
Containing reaction data for 8,400 different materials and powered by nearly 40 million quantum mechanics calculations, the team believes it’s the largest and most robust dataset of its kind.
Building a partnership (and a database)
Researchers with Meta’s Fundamental AI Research (FAIR) team were looking for ways to harness their machine learning prowess to address climate change. They landed on direct air capture as a promising technology and needed to find a partner with expertise in materials chemistry as it relates to carbon capture. They went straight to Georgia Tech.
David Sholl, ChBE professor, Cecile L. and David I.J. Wang Faculty Fellow, and director of Oak Ridge National Laboratory’s Transformational Decarbonization Initiative, is one of the world’s top experts in metal-organic frameworks (MOFs). These are a class of materials promising for direct air capture because of their cagelike structure and proven ability to attract and trap carbon dioxide.
Sholl brought Medford, who specializes in applying machine learning models to atomistic and quantum mechanical simulations as they relate to chemistry, into the project.
Sholl, Medford, and their students provided all the inputs for the database. Because the database predicts the MOF interactions and the energy output of those interactions, considerable information was required.
They needed to know the structure of nearly every known MOF—both the MOF structure by itself and the structure of the MOF interacting with carbon dioxide and water molecules.
“To predict what a material might do, you need to know where every single atom is and what its chemical element is,” Medford said. “Figuring out the inputs for the database was half of the problem, and that’s where our Georgia Tech team brought the core expertise.”
The team took advantage of large collections of MOF structures that Sholl and his collaborators had previously developed. They also created a large collection of structures that included imperfections found in practical materials.
The power of machine learning
Anuroop Sriram, research engineering lead at FAIR and first author on the paper, generated the database by running quantum chemistry computations on the inputs provided by the Georgia Tech team. These calculations used about 400 million CPU hours, which is hundreds of times more computing than the average academic computing lab can do in a year.
FAIR also trained machine learning models on the database. Once trained on the 40 million calculations, the machine learning models were able to accurately predict how the thousands of MOFs would interact with carbon dioxide.
The team demonstrated that their AI models are powerful new tools for material discovery, offering comparable accuracy to traditional quantum chemistry calculations while being much faster. These features will allow other researchers to extend the work to explore many other MOFs in the future.
“Our goal was to look at the set of all known MOFs and find those that most strongly attract carbon dioxide while not attracting other air components like water vapor, and using these highly accurate quantum computations to do so,” Sriram said. “To our knowledge, this is something no other carbon capture database has been able to do.”
Putting their own database to use, the Georgia Tech and Meta teams identified about 241 MOFs of exceptionally high potential for direct air capture.
Moving forward with impact
“According to the UN and most industrialized countries, we need to get to net-zero carbon dioxide emissions by 2050,” said Matt Uyttendaele, director of Meta’s FAIR chemistry team and a co-author on the paper.
“Most of that must happen by outright stopping carbon emissions, but we must also address historical carbon emissions and sectors of the economy that are very hard to decarbonize—such as aviation and heavy industry. That’s why CO2 removal technologies like direct air capture must come online in the next 25 years.”
While direct air capture is still a nascent field, the researchers say it’s crucial that groundbreaking tools—like the OpenDAC database made available in the team’s paper—are in development now.
“There is not going to be one solution that will get us to net-zero emissions,” Sriram said. “Direct air capture has great potential but needs to be scaled up significantly before we can make a real impact. I think the only way we can get there is by finding better materials.”
The researchers from both teams hope the scientific community will join the search for suitable materials. The entire OpenDAC dataset project is open source, from the data to the models to the algorithms.
“I hope this accelerates the development of negative-emission technologies like direct air capture that may not have been possible otherwise,” Medford said. “As a species, we must solve this problem at some point. I hope this work can contribute to getting us there, and I think it has a real shot at doing that.”
More information: Anuroop Sriram et al, The Open DAC 2023 Dataset and Challenges for Sorbent Discovery in Direct Air Capture, ACS Central Science (2024). DOI: 10.1021/acscentsci.3c01629
Journal information: ACS Central Science
Leave a Reply